Published on 07/06/2017 | Operations

When embarking on digital transformation, digitalization or significant changes to work process and re-engineering, it is often the maintenance organization and practices that are first considered. An essential ingredient for transformation is the application of machine learning and predictive analytics. These technologies have promised to remove unnecessary maintenance costs and shift industrial organizations to use predictive maintenance approaches. Approaches designed to help improve plant uptime and asset availability. However many organizations are still seeking the best ways to implement process change and achieve competitive advantage in this area.
According to ARC research and many reliability studies, 80 percent of all assets fail randomly despite having rigorous reliability and maintenance programs in place. Andy Chatha, president, and COO of ARC Advisory Group spoke about this during his keynote address to over 800 attendees at the recent ARC Forum in Orlando. Andy highlighting the need for companies to take advantage of emerging technologies and improve operational performance. Most would agree, the emergence of predictive and prescriptive analytics will be the next wave of improvements in asset performance, but the question remains – will this improvement be addressed by improvements in tools and work processes for maintenance or instead by improvements to operational and process engineering and process optimization.
Maintenance and reliability have improved asset performance to some degree with the help of simple condition monitoring and prognostics, but each have not delivered substantial improvements in uptime and cost reduction. Condition monitoring involves typical asset monitoring of specific asset-oriented variables such as vibration if the case is rotating equipment. Rules, manufacturer performance thresholds, and maintenance alerts are built into these systems. The science of prognostics, however, is based on the analysis of failure modes, detection of early signs of wear and aging, and fault conditions. A useful prognostics solution is implemented when there is sound knowledge of the failure mechanisms that are likely to cause the degradations leading to eventual failures in the system. Still useful for certain assets, but the problem with condition monitoring and prognostics each approach is it tends to keep a considerable narrow scope of the data analysis. Most prognostics solutions use a standard set of asset-specific historical condition and process data. Data points will typically including thermal, vibration, and lubricant analysis results.
Both Prognostics and Condition-based monitoring are still reactive approaches and have been used widely for decades. Still, many companies struggle with making significant improvements in predicting failures and extending the life of critical assets. Multiple industry experts would cite the fact that 3-5 percent of all maintenance is predictive, while the balance is break-fix or scheduled based on an interval set by the OEM. Each method also ignores the most important factors such as operations – how the equipment is operated, variability in process conditions upstream and downstream of the asset and changes in composition and quality of the process fluid. It has only been since the emergence of machine learning, big data, and analytics that has created the opportunity to more precisely look at the data sets across process variables and asset health. Many industry experts also believe this variability or “process abuse’ is a very likely cause of the so-called 80 percent randomness of failures.
In the process industries, it is the Operations group that is most knowledgeable of the process, and its inherent variability and impact on assets. This would include process optimization engineers, process operators, and other subject matter experts working to improve production operations and not necessarily the direct maintenance and asset reliability experts. Therefore one might come to the conclusion that any predictive maintenance or asset reliability strategy might begin with an overarching operations strategy and weigh heavily on the skills of the process engineer. The process engineer (and not the maintenance and reliability engineer), has the ability to interpret the process data across the spectrum of the process and any assets.
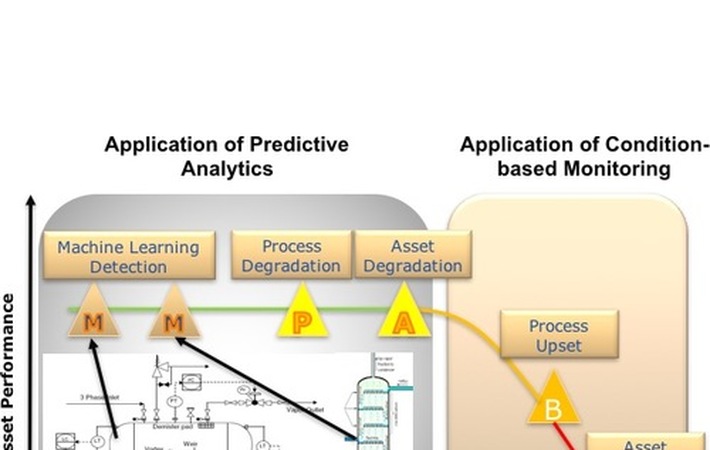
Note in the P-F curve above: Point M- Machine learning detection occurs by using automated data collection of historical multi-variate, with equipment specific algorithms or machine learning, and typically using automated data collection & analysis. Pattern identification points to an explicit diagnosis of root cause and indicates a precise action to change an outcome. The system includes upstream and downstream process variables. Usually, an alert would be sent to an SME providing advice and probability of a future failure weeks or months in advance. Prescriptive advice would include altering the process operation to avoid a future failure of the asset (point C)
This article was originally posted on ARC Advisory Group.